
Apache Spark Unified Memory Model
| Configuration Parameter | Default | Purpose & Tuning Tip |
|---|---|---|
| spark.memory.fraction | 0.6 |
Determines the fraction of the (JVM heap - 300MB) used for execution and storage.
Tip: Increase this to 0.8 if your job has minimal user-defined data structures to allow more room for Spark operations.
|
| spark.memory.storageFraction | 0.5 |
The portion of the Unified Memory that is immune to eviction by execution tasks.
Tip: If you use `.cache()` heavily, keep this at 0.5. If you prioritize shuffles/joins over caching, you can lower this.
|
| spark.memory.offHeap.enabled | false |
Enables Project Tungsten's off-heap memory management.
Tip: Turn this on and set spark.memory.offHeap.size to reduce Garbage Collection (GC) pauses in high-scale jobs.
|
| spark.executor.memoryOverhead | 10% |
Extra memory allocated per executor for VM overhead, interned strings, and other native overheads.
Tip: Increase this if you see "YARN Container killed by external killer" errors.
|
Managing Spark memory requires understanding the separate roles of the Driver (the orchestrator) and the Executors (the workers).
Risk: Large
collect() calls pull data here, causing OutOfMemory (OOM).
--conf spark.driver.memory=4gExecutor Memory: Where the real heavy lifting happens. It is split into storage (caching) and execution (joins/shuffles).
--conf spark.executor.memory=8g
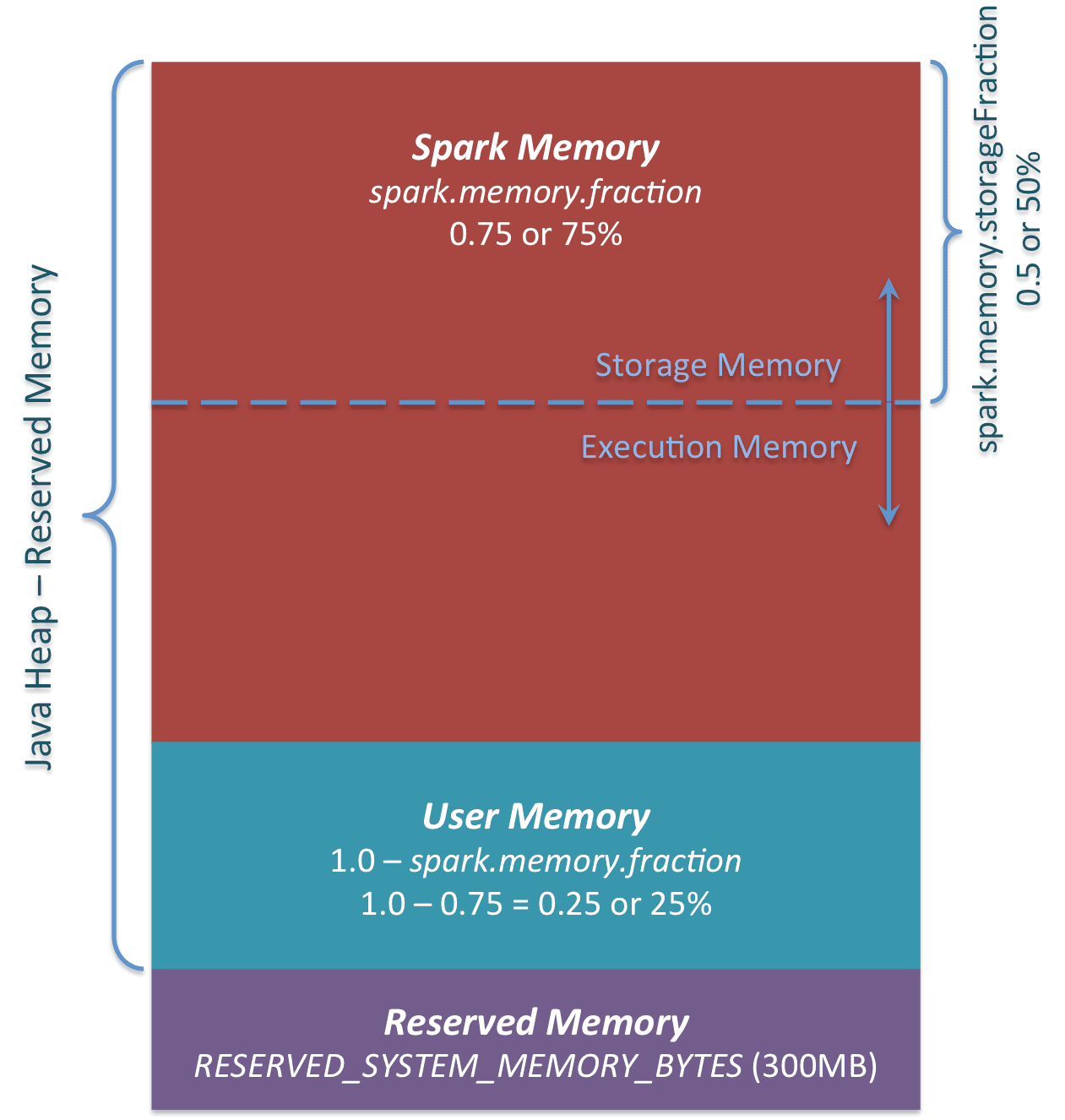
In modern Spark (1.6+), memory is Unified. This means Execution and Storage share a flexible boundary. This is part of JVM Heap and it is divided into two parts.
First is reserved for system overheads (300 MB). Second is for execution and storage memory which is combined, therefore, unified memory model.
- Execution Memory: Used for shuffles, joins, and sorts. It is short-lived.
- Storage Memory: Used for caching RDDs/DataFrames and Broadcast variables.
The Unified region (M) is broken down as follows: JVM Heap - 300 MB (system overhead) * spark.memory.fraction (0.6 by default), which leaves 40% for user data structures, metadata, etc.
Storage Region = M * spark.memory.storageFraction (0.5 by default), Data cached here is immune to eviction for execution reasons. <\br> Execution can evict storage blocks if needed but storage cannot do that to execution. If memory is full, data is spill to disk., so for cache heavy application increase the storageFraction value, for shuffle heavy, decrease it.
The Golden Rule: If execution tasks need more memory, they can evict cached data from storage. However, storage cannot evict execution.
It is managed by OS or Spark and not by JVM. For large-scale jobs, JVM Garbage Collection (GC) can become a bottleneck. Off-Heap Memory allows Spark to manage memory directly via the OS. Since it is not managed by JVM, manual handling is required and native memory usage has to be monitered. You can always use SparkUI dsashboard for mem usage breakdown.
spark.memory.offHeap.enabled true spark.memory.offHeap.size 4g
OOM can occur from skewed data, larger objects not being purged, etc. and these can be mitigated with proper partitioning, broadcasting small tables, or simply increasing memory. But it all depends on the case.
DataFrames use the Tungsten engine, which stores data in binary format, bypassing the overhead of Java objects.
Only cache if a table is used 3+ times. Excessive caching starves the execution pool and triggers spills to disk.
Too many partitions create metadata overhead; too few lead to huge "skews" that crash individual executors.
For PySpark/Pandas, always increase spark.executor.memoryOverhead to account for non-JVM memory usage.
In the ecosystem of big data processing, Spark Unified Memory Management is the engine's most critical internal regulator, acting as the primary lever between high-performance execution and the dreaded OutOfMemory (OOM) error.
Unlike earlier iterations that used static memory partitioning, modern Spark employs a dynamic model that balances two main types of memory: Execution and Storage. Managing this effectively is vital because Spark’s "in-memory" speed relies entirely on how well it handles data shuffles, joins, and caching within the finite limits of the JVM heap. A poorly tuned memory model leads to excessive disk spilling or garbage collection (GC) overhead, which can turn a ten-minute job into a multi-hour failure.
The Spark Memory Model at a Glance
Spark divides the memory available to an executor into four distinct segments:
Reserved Memory: A fixed amount (usually 300MB) set aside for Spark’s internal objects and recovery.
User Memory: Used for storing data structures created by the user (e.g., UDFs, RDD transformations) that are not managed by Spark.
Spark Memory (Unified): The heart of the system, further subdivided into:
Execution Memory: Used for computation tasks like shuffles, joins, and aggregations.
Storage Memory: Used for caching, broadcasting variables, and unrolling serialized data.
Off-Heap Memory: (Optional) Memory residing outside the JVM heap, useful for reducing GC pressure and handling massive datasets more efficiently.
Under the Unified approach, the boundary between Execution and Storage is flexible. If Execution memory is idle, Storage can borrow it to cache more data; conversely, if the execution engine needs more space for a heavy join, it can "evict" cached data from Storage to reclaim its territory, ensuring that the most compute-intensive tasks always have the resources they need to finish.