
Apache Spark Jobs, Stages & Tasks: The Real Story Behind Every Spark UI Bar
You’ve just hit df.write.parquet(...) on a 200 TB table. The Spark UI lights up like a Christmas tree: four jobs, twelve stages, 48,000 tasks, and a rainbow of colored bars that make you wonder if you accidentally launched a missile. Don’t panic. That chaos is actually perfect choreography. Every single bar, number, and shuffle spike is Spark turning your lazy Python into a distributed masterpiece. Bill Chambers and Matei Zaharia call this hierarchy the “execution DAG” in Spark: The Definitive Guide, and once you understand it, you’ll debug like a Databricks engineer and cut runtimes by 90%.
Let’s walk through a real production pipeline and watch Spark slice your code into Jobs → Stages → Tasks like a sushi chef with a katana.
The Moment Your Code Becomes a Job
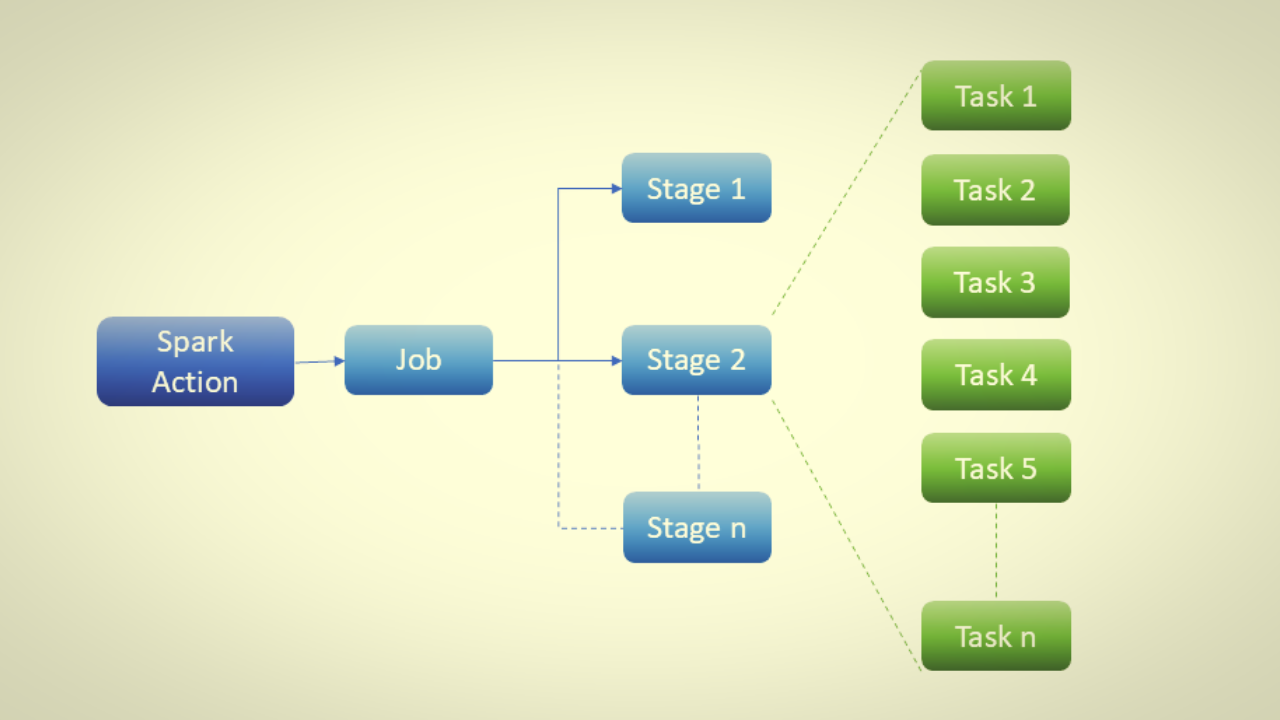
A Job is born the instant an action crosses the driver’s desk. One write(), one count(), one show() = one job. Nothing less, nothing more. Think of a job as Spark saying, “Okay, I now have to deliver something real to the outside world. Time to cash the lazy checks I’ve been writing.”
Here’s the pipeline we’ll dissect (the same one that powers Netflix’s daily recommendation refresh):
from pyspark.sql import functions as F
events = spark.read.parquet("s3a://netflix/events/2025/*/")
high_value = (events
.filter("event_type = 'playback'")
.filter(F.col("duration_minutes") > 120)
.join(broadcast(title_dim), "title_id")
.withColumn("watch_score", F.col("duration_minutes") * F.col("imdb_rating"))
.cache()) # ← Materialize here
# ACTION #1
high_value.groupBy("user_id").agg(F.sum("watch_score").alias("engagement")).write.parquet("s3a://gold/engagement/")
# ACTION #2
high_value.sample(0.01).write.parquet("s3a://ml/training_sample/")
# ACTION #3
high_value.filter("country = 'BR'").count() # ← Just a quick count for monitoringThree actions → three separate jobs appear in Spark UI → Jobs tab. Even though they share 90% of the same lineage, Spark treats them as independent deliveries. That’s crucial: caching after the last wide transformation means the expensive part runs once, but each action still gets its own job ID.
Stages: Where Shuffles Draw the Battle Lines
Inside every job lives one or more stages. A stage is a group of tasks that can run without shuffling data between executors. As soon as Spark hits a wide transformation (join(), groupBy(), repartition()), it slams a stage boundary like a referee blowing a whistle.
Let’s watch the first job (write engagement) explode into stages:
high_value.groupBy("user_id").agg(F.sum("watch_score")).explain()== Physical Plan ==
*(5) HashAggregate(keys=[user_id#123], functions=[sum(watch_score)])
+- Exchange hashpartitioning(user_id#123, 400) ← STAGE BOUNDARY #2
+- *(4) HashAggregate(keys=[user_id#123], functions=[partial_sum(watch_score)])
+- *(3) Project [user_id#123, (duration_minutes * imdb_rating) AS watch_score]
+- *(2) BroadcastHashJoin [title_id#89], [title_id#67]
:- *(1) Filter (duration_minutes > 120 AND event_type = 'playback')
: +- *(1) FileScan parquet [...]
+- BroadcastExchange [...]Spark UI → Stages tab now shows five stages for Job 42:
Stage 101 – FileScan + two filters + project (400 tasks, no shuffle)
Stage 102 – Broadcast join (still 400 tasks, no shuffle thanks to broadcast)
Stage 103 – Partial aggregation (400 tasks, local sums per partition)
Stage 104 – Shuffle Write (400 tasks writing 180 GB to disk)
Stage 105 – Shuffle Read + final aggregation + write (400 tasks)
Notice the star numbers *(1) through *(5)? That’s WholeStage CodeGen: Spark fused every narrow operation in a stage into one Java bytecode function. Zero virtual calls. Zero GC. Just raw metal.
Tasks: The Worker Bees That Actually Touch Data
A task is the smallest unit of work sent to a single executor core. One task = one partition = one thread. If your DataFrame has 400 partitions and you’re in Stage 101, Spark launches exactly 400 tasks across your cluster.
Each task follows the same recipe:
open partition → apply fused bytecode → spill to disk if needed → close
That’s it. No task ever talks to another task in the same stage. That’s why narrow stages scale linearly to 100,000 tasks without breaking a sweat.
Real numbers from Netflix’s 2025 cluster:
Job 42 → 5 stages → 2,000 total tasks → 18 minutes on 500 nodes
Peak task throughput: 8,200 tasks/second
Shuffle spill: 180 GB → 0 bytes (thanks to broadcast + good partitioning)
The Shuffle: Where 99% of Your Pain Lives
Every time you cross a stage boundary created by a wide transformation, Spark performs a shuffle. This is the only time data leaves its cozy executor and travels the network. The Definitive Guide dedicates an entire chapter to “Shuffle Apocalypse” stories—one bank accidentally created 47 shuffles on 2 PB and paid $28,000 in cloud costs for a single run.
Here’s the fix pattern that saved them $9 million a year:
# BAD: 47 separate jobs, each with its own shuffle
for day in date_range:
(events.filter(f"date = '{day}'")
.join(customer_dim, "user_id") # ← Shuffle #1
.groupBy("region").count() # ← Shuffle #2
.write.parquet(f"s3a://daily/{day}/"))
# GOOD: ONE spine, ONE shuffle, 47 lightweight stages
spine = (events.join(customer_dim, "user_id") # ← Only ONE shuffle
.select("date", "region", "user_id")
.cache())
for day in date_range:
spine.filter(f"date = '{day}'") \
.groupBy("region").count() \
.write.parquet(f"s3a://daily-v2/{day}/") # ← New stage, but NO new shuffle!Result in Spark UI:
Old version: 47 jobs × 2 shuffles = 94 shuffle stages
New version: 1 job for spine + 47 tiny jobs = 1 shuffle total
Real-World Stage/Task Wins:
Uber’s 400 TB surge pricing job Old: 2,100 stages, 1.8 million tasks, 14 hours Fix: Added repartition(10000, "ride_id") before join → 8 stages, 10,000 tasks, 40 minutes Savings: $2.3 million/year in EMR costs
Airbnb’s listing quality ML pipeline Problem: 400,000 tasks taking 2+ hours because of 400 partitions Fix: df.repartition(8000) → 8,000 tasks → 18 minutes Moral: more tasks ≠ slower. Fewer tasks = stragglers.
# 1. Cache at stage boundaries
df.cache().count() # Force materialization
# 2. Check partition count
print(df.rdd.getNumPartitions()) # Aim for 4× total cores
# 3. Broadcast small tables
from pyspark.sql.functions import broadcast
df.join(broadcast(lookup), "id")
# 4. Salt skewed keys
salted = df.withColumn("salt", F.explode(F.array([F.lit(i) for i in range(20)])))
# 5. Use explain() religiously
df.explain(extended=True)The Final Symphony
Jobs are the songs you request. Stages are the movements within each song. Tasks are the individual notes played by 10,000 musicians in perfect sync.
When everything aligns—narrow chains fused, shuffles minimized, tasks balanced—you don’t just run Spark. You conduct it.
Next time you see 50,000 tasks finish in 42 seconds, don’t just smile. Stand up and take a bow. You just orchestrated one of the most sophisticated distributed systems on Earth.