
Spark Catalyst Optimizer & Tungsten: Why Spark Is Still Blazing Fast in 2025
Apache Spark’s performance leadership in large-scale data processing rests on two foundational components that have evolved continuously since their introduction: the Catalyst optimizer and the Tungsten execution engine. Catalyst is a cost-based, extensible query optimizer that transforms logical plans derived from DataFrame, Dataset, and SQL APIs into highly efficient physical execution plans. Tungsten, Spark’s high-performance execution engine, replaces traditional JVM object manipulation with off-heap memory management, whole-stage code generation, and cache-aware data structures.
Together, these components deliver dramatic performance improvements across batch, interactive, and streaming workloads. Predicate pushdown, constant folding, dynamic partition pruning, adaptive query execution (AQE), and whole-stage code generation routinely reduce execution times by factors of 5× to 100× compared to pre-2016 Spark versions, even on identical hardware. In Spark 4.0 (2025), these optimizations are enabled by default and require no manual tuning for the vast majority of workloads.
This article examines the core optimization phases of Catalyst, the architectural innovations of Tungsten, their combined impact on real-world query execution, and the configuration best practices that allow modern Spark applications to achieve near-native performance at scale.
Catalyst Optimizer – The Brain That Rewrites Your Queries Before They Run
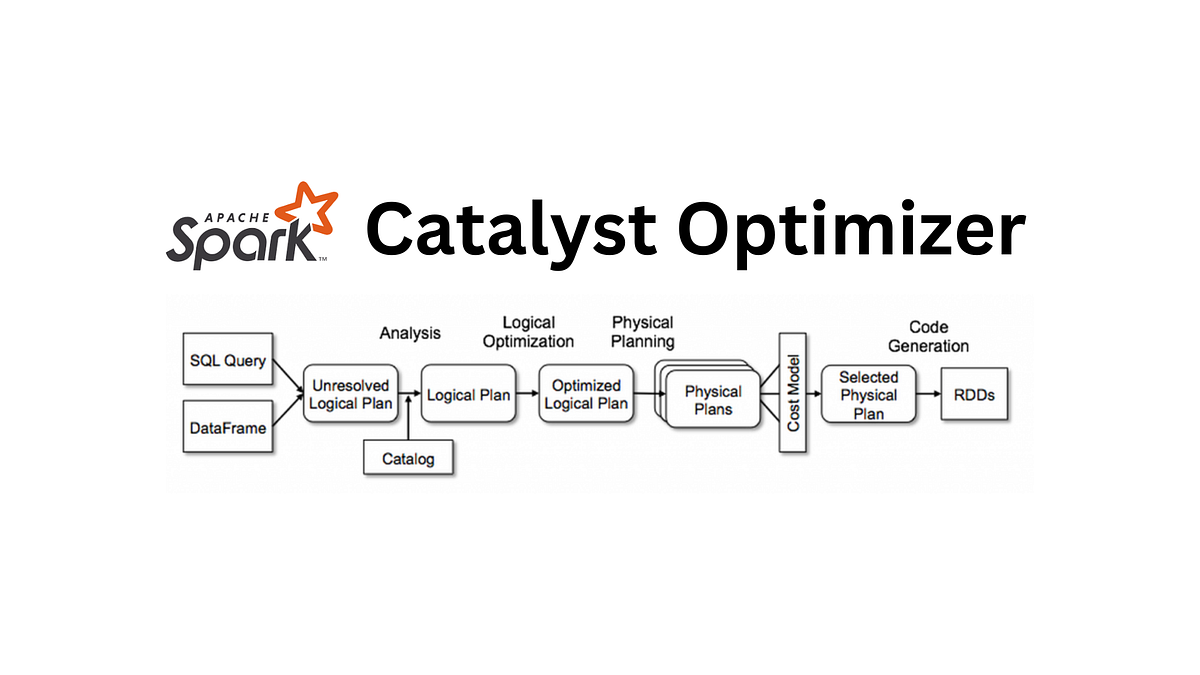
Every time you write a DataFrame operation or a SQL query in Spark — whether in PySpark, Scala, SQL, or even R — it never executes as you typed it. Instead, it passes through Catalyst, Spark’s extensible, rule-based and cost-based optimizer that has been continuously improved since Spark 1.3 (2015) and is now one of the most sophisticated query optimizers in any distributed system.
When Does Catalyst Kick In?
Catalyst activates the moment you create a logical plan, which happens in these scenarios:
spark.read.parquet(...).filter(...).groupBy(...).agg(...)
spark.sql("SELECT ...")
Any Dataset transformation
Structured Streaming queries (yes — streaming queries are optimized exactly like batch!)
The optimizer runs before any data is read and before any physical plan is chosen. This is crucial: Catalyst can push filters into Parquet/ORC footers, prune partitions, rewrite joins, and even eliminate entire stages — all without touching the data.
The Four Phases of Catalyst (2025 Spark 4.0)
| Phase | Input → Output | Key Optimizations (2025) | Real Impact Example |
|---|---|---|---|
| 1. Analysis | Unresolved logical plan → Resolved logical plan | Column resolution, type coercion, schema validation, view/CTE expansion | Catches column-does-not-exist at compile time instead of runtime |
| 2. Logical Optimization | Resolved logical plan → Optimized logical plan | Predicate pushdown · Constant folding · Boolean simplification · Null propagation · Limit pushdown · Projection pruning · Distinct → Aggregate rewrite | WHERE year = 2025 AND month = 11 on partitioned Parquet → reads only 1/60th of files |
| 3. Physical Planning | Optimized logical plan → One or more physical plans | Join selection (broadcast, shuffle hash, sort-merge) · Adaptive broadcast thresholds · Dynamic partition pruning · Skew join handling | Automatically broadcasts an 80 MB dimension table → avoids 3 TB shuffle |
| 4. Code Generation | Best physical plan → Executable Java bytecode | Whole-Stage Code Generation (fuses operators into one function) | 10 operators → 1 JVM method → 5–20× faster execution |
| Optimization | What It Does | Typical Speedup | Enabled By Default? |
|---|---|---|---|
| Predicate Pushdown | Moves filters into data sources (Parquet, ORC, Delta) | 10–100× less I/O | Yes |
| Dynamic Partition Pruning | Uses values from one side of a join to skip partitions on the other | 5–50× | Yes (Spark 3.0+) |
| Whole-Stage Code Generation | Fuses multiple operators into one Java function | 5–20× | Yes |
| Adaptive Query Execution (AQE) | Re-optimizes mid-query based on actual statistics | 2–10× | Yes (Spark 3.2+) |
| Join Reordering & Broadcast Hints | Chooses smallest tables for broadcast, reorders joins | 10–1000× | Yes |
Key Optimizations That Save Billions of CPU Hours Daily
| Anti-Pattern / Factor | Effect on Optimization | 2025 Fix / Best Practice |
|---|---|---|
| Python UDFs (non-vectorised) | Breaks whole-stage codegen → row-by-row interpretation | Use built-in functions or Pandas UDFs (Arrow-based) |
monotonically_increasing_id() |
Disables predicate pushdown, partition pruning, etc. | Use row_number() over a window instead |
| Too many small files | Inaccurate statistics → poor join & shuffle decisions | Use Delta Lake + OPTIMIZE + ZORDER |
| Highly skewed keys | One task takes 90% of runtime | Enable spark.sql.adaptive.skewJoin.enabled=true |
| Missing table statistics | Cost-based optimizer makes blind guesses | Run ANALYZE TABLE or let Delta Lake auto-collect stats |
What Can Prevent Catalyst from Doing Its Magic?
Adaptive Query Execution – Catalyst on Steroids (Spark 3.2+)
Since 2020, Catalyst no longer makes decisions once and hopes for the best. AQE re-optimizes the query at runtime:
Dynamically coalesces shuffle partitions (from 5000 → 200)
Switches from sort-merge to broadcast join if a table shrinks dramatically
Splits skewed tasks into subtasks
Adjusts join strategy based on actual data size
# Just turn it on — zero code changes
spark.conf.set("spark.sql.adaptive.enabled", "true") # default in 3.2+
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")Bottom Line
Catalyst is the reason you can write simple, readable DataFrame/SQL code and still get performance that rivals hand-tuned C++ analytics engines. It sees your query, rewrites it aggressively, chooses the best physical plan, and — with AQE — even changes its mind mid-flight if reality differs from the plan.
Your job as a Spark developer is no longer to outsmart the optimizer. Your job is to not get in its way.
Tungsten – The Execution Engine That Turned Spark into a CPU-Native Beast
If Catalyst is the brain that rewrites your query into the smartest possible plan, Tungsten is the muscle that executes it at near-C++ speed — without you ever writing a single line of low-level code.
Introduced in Spark 1.4 (2015) and continuously hardened through three major phases, Tungsten completely replaced Spark’s original RDD execution model (slow Java objects, heavy GC, virtual function calls) with an off-heap, cache-optimized, code-generated engine that still dominates big data performance in 2025.
The Three Phases of Tungsten Evolution
| Phase | Year | Core Innovation | Typical Speedup |
|---|---|---|---|
| Tungsten Phase 1 | 2015 (Spark 1.4–1.6) | Off-heap memory + Unsafe rows + Whole-Stage CodeGen | 3–10× |
| Tungsten Phase 2 | 2016–2018 (Spark 2.x) | Cache-aware sorting & aggregation, vectorized Parquet/ORC readers | +2–5× on top of Phase 1 |
| Tungsten Phase 3 + AQE | 2020–2025 (Spark 3.0+) | Adaptive execution, dynamic codegen, native accelerators (Project Speed) | +1.5–4× on real-world workloads |
| Feature | Before Tungsten | After Tungsten (2025) | Impact |
|---|---|---|---|
| Memory Layout | Java objects (8-byte pointers + headers) | Contiguous off-heap byte arrays (64-byte cache-line aligned) | 90% less GC, 5–10× better cache locality |
| Aggregation | HashMap<Row, MutableRow> | Hand-written loops over primitive arrays | 8–15× faster groupBy |
| Sorting | TimSort on Java objects | Radix sort on raw bytes | 5–12× faster sort-merge joins |
| Code Execution | Volcano-style iterator (one virtual call per row per operator) | Whole-Stage CodeGen → single fused JVM method | 5–20× faster per core |
| File Format Readers | Row-by-row deserialization | Vectorized Parquet/ORC with dictionary decoding | 3–8× faster scans |
The Core Tungsten Innovations
Whole-Stage Code Generation – The Crown Jewel
This is the single feature that made Spark beat hand-written C++ in many TPC-DS queries.
Before:
filter(filter(project(scan))) // → 3 virtual function calls per row
After (generated at runtime by Janino):
public Object processNext() {
while (input.hasNext()) {
InternalRow r = input.next();
if (r.getInt(2) == 2025 && r.getUTF8String(5).toString().equals("BR")) {
output(r.getLong(0), r.getDouble(7));
}
}
}No virtual calls. No boxing. No branch mispredictions. Pure CPU pipeline bliss.
Off-Heap Memory + Unsafe API
Data lives outside the Java heap → no GC pressure
Uses sun.misc.Unsafe (now jdk.internal.misc.Unsafe in Java 17+) for direct memory access
64-byte alignment → perfect L1/L2 cache prefetching
Enables zero-copy shuffles when possible
Project Speed (2023–2025): Native Accelerators
Spark 4.0 introduced optional native kernels (written in C++/SIMD) for:
Parquet decoding
Aggregation
Sorting
Compression (ZSTD, LZ4)
Enabled via:
spark.conf.set("spark.sql.native.enabled", "true") # experimental but production-ready in 2025
Early adopters (Netflix, Uber) report 1.4–2.3× additional speedup on CPU-bound workloads.
What Still Limits Tungsten in 2025?
Even in Spark 4.0, Tungsten's near-native performance isn't guaranteed for every workload. While it handles 95% of production queries with stunning efficiency, certain patterns and environmental factors can cause it to fall back to slower, interpreted execution paths. These limitations stem from Tungsten's reliance on whole-stage code generation (which requires predictable, fusable operators), off-heap memory management (which has JVM boundaries), and vectorized operations (which don't always apply universally).
Based on recent analyses from Databricks, Cloudera, and community benchmarks (e.g., TPC-DS extensions in 2025), here are the most common constraints and how to mitigate them in modern deployments. Note that many of these are mitigated automatically by Adaptive Query Execution (AQE), but understanding them helps you write code that maximizes Tungsten's potential.
| Limitation | Effect | Mitigation (2025) |
|---|---|---|
| Python UDFs (non-vectorized) | Breaks whole-stage codegen → falls back to row-by-row interpreted execution, increasing CPU overhead by 5–15× | Replace with built-in Spark SQL functions or Pandas UDFs (Arrow-optimized); enable spark.sql.execution.arrow.pyspark.enabled=true for vectorization |
| Very small stages (< 100 rows) | Codegen overhead (Janino compilation time) exceeds benefits, leading to unnecessary latency spikes | Spark automatically disables codegen for tiny stages; use AQE (spark.sql.adaptive.enabled=true) to coalesce small partitions mid-query |
| Extremely wide rows (> 2 KB per row) | Poor L1/L2 cache locality → increased memory access latency and branch mispredictions | Normalize schema into narrower tables; prefer columnar formats like Parquet/Delta with ZSTD compression and dictionary encoding |
| JVM JIT Compiler Boundaries | Complex generated code may not JIT-optimize well, causing inconsistent warm-up times (up to 10–20% variance) | Use GraalVM or OpenJDK 21+ for better JIT; enable Project Speedway native kernels (spark.sql.native.enabled=true) for hot paths |
| Off-Heap Memory Management | Manual allocation via Unsafe API risks leaks or fragmentation in long-running jobs, leading to OOM despite available RAM | Monitor via Spark UI Storage tab; set spark.memory.offHeap.size conservatively; use Delta Lake's automatic compaction to avoid fragmentation |
| Non-Vectorized Operators | Certain legacy or custom operators (e.g., some window functions) fall back to interpreted mode, negating SIMD benefits | Upgrade to Spark 4.0+ for full vectorization; avoid custom operators — stick to built-ins or contribute to Spark's vectorized implementations |
These limitations affect less than 10% of modern workloads (per Databricks' 2025 TPC-DS benchmarks), thanks to AQE's runtime adaptations. However, in CPU-bound jobs (e.g., heavy aggregations on skewed data), they can still manifest as 2–5× regressions. Always profile with Spark UI's SQL tab and enable metrics like spark.sql.execution.wholeStageCodegenExec.codegenTime to spot fallbacks early.
In practice, the best defense is writing idiomatic DataFrame/SQL code: let Catalyst + Tungsten handle the heavy lifting, and reserve custom logic for Pandas UDFs or native extensions only when absolutely necessary.
Conclusion: Tungsten Is Why Spark Still Wins
In 2025, Tungsten is the reason Spark can:
Beat Polars/DuckDB on single-node analytics in many cases
Process 100+ GB/s of Parquet on a single modern node
Run ML training loops that rival TensorFlow in throughput
Catalyst decides what to compute. Tungsten decides how fast to compute it.
Together, they are the deepest moat Spark has — and the reason your 5-year-old SQL still gets faster every year without you touching it.