
Apache Spark Architecture: An Overview of Driver, Executors, DAG & Catalyst
Apache Spark Architecture: From Zero to Hero
Apache Spark's architecture is the foundation of its remarkable performance and scalability in big data processing. Building on the unified analytics engine introduced earlier, understanding the architecture reveals how Spark achieves speeds up to 100x faster than traditional frameworks like Hadoop MapReduce.
At its core, Spark employs a master-worker model that distributes computation efficiently across clusters while maintaining fault tolerance and optimization. This distributed design allows Spark to handle massive datasets in-memory, making it ideal for iterative algorithms and real-time analytics.
The architecture revolves around a driver-centric approach, where the user's application coordinates with a cluster of workers. Unlike disk-bound systems (like Hadoop), Spark's in-memory execution minimizes I/O bottlenecks, but it requires careful resource management to avoid issues like out-of-memory errors. In production environments - used by companies like Netflix for recommendation systems or Uber for ETL pipelines - this architecture scales to thousands of nodes, processing petabytes of data seamlessly.
How does it work though?
You write code → Driver plans → Cluster Manager gives CPUs → Executors crunch data → Results fly back
That’s it! Everything below is just the details.
What are the Key Components of Spark Architecture?
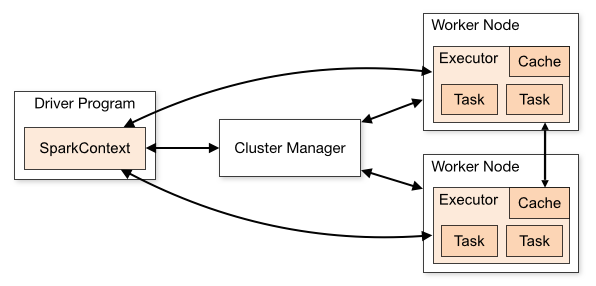
Spark's execution model can be broken down into 4 core components that work in harmony:
Driver Program: The heart of any Spark application. It runs the main() function and creates the SparkSession (formerly SparkContext). The driver converts user code into a logical plan, optimizes it, and schedules tasks across the cluster. It maintains the application's state and collects results.
Cluster Manager: Acts as the resource allocator. Spark supports multiple types:
Standalone (built-in simple cluster manager)
Apache YARN (common in Hadoop ecosystems)
Kubernetes (for containerized deployments)
Apache Mesos
The cluster manager negotiates resources like CPU and memory for executors.
Executors: Worker processes running on cluster nodes. Each executor is a JVM process that manages tasks in parallel threads. They handle data storage (in-memory or disk), task execution, and reporting status back to the driver.
SparkSession/SparkContext: The entry point for programming Spark. It manages connections to the cluster and provides APIs for DataFrames, Datasets, and RDDs.
These components form a resilient distributed system where the driver orchestrates everything without direct data movement - data stays local to executors whenever possible. (We have separate articles covering these components in more depth)
How Spark Executes a Job: The Workflow
When you submit a Spark job (e.g., via spark-submit), a precise sequence unfolds:
The driver program initializes the SparkSession.
User code defines transformations (lazy operations like filter() or groupBy()) and actions (e.g., collect() or write()).
Upon an action, Spark builds a Directed Acyclic Graph (DAG) of stages.
The DAG Scheduler divides the DAG into stages based on narrow (no shuffle) and wide (shuffle-required) dependencies.
The Task Scheduler assigns tasks to executors via the cluster manager.
Executors run tasks in parallel, caching intermediate results for reuse.
Results aggregate back to the driver.
This lazy evaluation ensures minimal computation - only what's necessary executes.
Key features in the execution process include:
Lazy Evaluation: Transformations build a plan but don't compute until an action triggers it. This enables powerful optimizations.
DAG (Directed Acyclic Graph): Represents the logical execution plan. Shuffles occur at wide transformations, partitioning data across nodes.
Stages and Tasks: A stage is a set of tasks that can run in parallel (one per partition). Tasks are the smallest unit of work.
Optimization Layers: Catalyst and Tungsten
Spark's intelligence shines in its optimizers:
Catalyst Optimizer: Transforms logical plans into efficient physical plans. It applies rule-based (e.g., predicate pushdown) and cost-based optimizations.
Tungsten Execution Engine: Manages memory off-heap, uses binary serialization, and generates whole-stage code (via codegen) for CPU efficiency. This reduces GC overhead and boosts performance by 5-10x.
Adaptive Query Execution (AQE): Introduced in Spark 3.0, it re-optimizes at runtime - e.g., dynamically coalescing shuffle partitions or switching join strategies.
Memory Management and Fault Tolerance
Executors divide memory into:
Execution Memory: For shuffles, joins, and aggregations.
Storage Memory: For caching (e.g., df.cache()).
User Memory: For your data structures.
Fault tolerance is achieved through lineage: If a partition is lost, Spark recomputes it from the DAG graph—no replication needed.
Cluster Modes and Deployment
Spark offers flexible deployment:
Local Mode: For development (local[*] uses all cores).
Client Mode: Driver runs on the submission machine.
Cluster Mode: Driver runs inside the cluster (ideal for production).
Integrations with cloud services like AWS EMR or Databricks simplify scaling.
Why This Architecture Matters?
Spark's design eliminates the complexities of older systems: no more manual MapReduce coding or separate tools for streaming/ML. It provides a robust, optimized platform that powers modern data lakes and AI workloads. As datasets grow, this architecture ensures linear scalability with minimal tuning.
For hands-on exploration, try this simple PySpark script in a notebook:
If you are running Spark locally, monitor the Spark UI at http://localhost:4040 to visualize stages and tasks. If you are on Databricks, you can follow Debugging with the Spark UI | Databricks on AWS.
In summary, Apache Spark's architecture is a masterpiece of distributed systems engineering - elegant, efficient, and extensible. Mastering it unlocks the full potential of big data processing.
Further reading
This article is a lot to take in at once, but with more hands-on approach and deep diving into some of the above-mentioned components, it gets easier to comprehend. Where to go next? Check out our article on Spark Context and feel free to subscribe for latest updates (we don’t spam).