
A Beginner’s Guide to Apache Spark: Introduction, Features, and Ecosystem
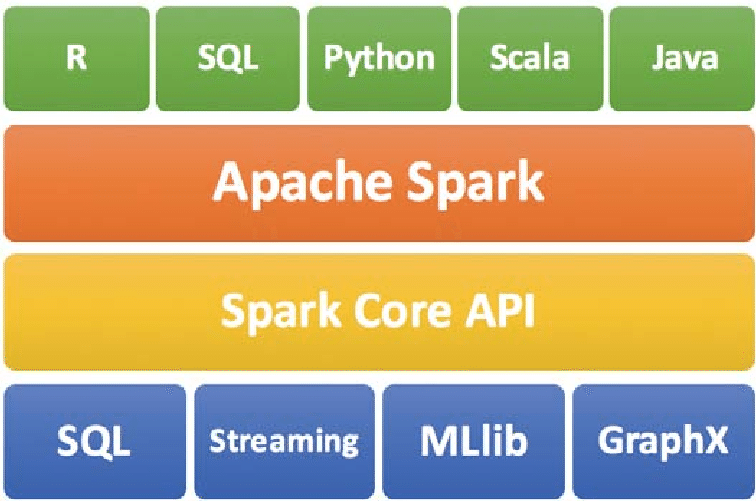
“Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.”
What is Apache Spark?
Apache Spark is an open-source, distributed computing framework designed for fast, large-scale data processing. Launched in 2010 at UC Berkeley's AMPLab and becoming an Apache top-level project in 2013, Spark has become a cornerstone of modern data engineering and big data analytics.
At its core, Spark is a unified analytics engine that handles batch processing, real-time streaming, machine learning, and SQL queries - all in one platform. Unlike traditional tools like Hadoop MapReduce, which are slow and disk-heavy, Spark processes data in-memory for lightning-fast performance. It's written in Scala but supports APIs in Java, Python (PySpark), R, and SQL.
Why use Spark? In 2025, with data exploding from IoT and AI, Apache Spark processes petabytes faster than ever—up to 100x quicker than Hadoop. Ready to dive in? Spark scales to handle petabytes of data across thousands of machines. It's used by companies like Netflix, Uber, and Databricks (founded by Spark's creators) for everything from recommendation engines to fraud detection.
What are the main features of Spark?
In-memory computation: Processes data in RAM for speeds up to 100x faster than disk-based frameworks, with fallback to disk.
Distributed processing: Scales horizontally across clusters to handle petabyte-scale datasets in parallel.
Unified Engine: One platform for batch, streaming (Structured Streaming), SQL, ML (MLlib), and graph processing (GraphX).
Multi-Language APIs: High-level support for Python (PySpark), Scala, Java, R, and SQL.
Lazy evaluation: Builds an execution plan (DAG) upfront; computation only triggers on actions, optimizing resource use.
Immutable (via RDDs): Core data structures are immutable, ensuring consistency and safe sharing across nodes.
Fault-tolerant: Uses data lineage to automatically recover lost partitions without restarting jobs.
Cache & persistence: Explicitly store intermediate results in memory or disk for faster iterative algorithms.
Multiple cluster manager: Deploy on YARN, Mesos, Kubernetes, or Standalone mode for flexible environments.
Built-in Optimization (DataFrames/Datasets): Catalyst optimizer and Tungsten engine automatically tune for performance.
Real-Time Streaming: Handles live data with exactly-once semantics and micro-batch processing.
What does Spark ecosystem consists of?
At the heart is Spark Core, which provides the essential building blocks:
Task scheduling, memory management, and fault tolerance.
The RDD (Resilient Distributed Dataset) API for low-level control.
Support for in-memory computing across distributed clusters.
Stacked on top are specialized modules that extend Spark for real-world use cases:
Spark SQL: Turn Spark into a distributed SQL engine. Query structured data with ANSI-compliant SQL or DataFrame APIs. Perfect for data analysts - write familiar queries that run at scale, with automatic optimizations via Catalyst.
Spark Streaming (Structured Streaming): Process live data streams in real-time. Ingest from sources like Kafka or Flume, apply transformations, and output to dashboards or databases. It handles micro-batches or continuous processing with exactly-once guarantees.
MLlib: Scalable machine learning library. Build and deploy models for classification, regression, clustering, and recommendations. Algorithms run distributed, reusing data in-memory for iterative training - ideal for large datasets.
GraphX: For graph-parallel computations. Analyze networks (e.g., social connections or fraud patterns) with APIs for PageRank, connected components, and more.
These libraries share the same cluster, APIs, and data formats, reducing complexity. Spark also integrates effortlessly with external tools:
Storage: Hadoop HDFS, Apache Cassandra, AWS S3, Azure Blob.
Ingestion: Apache Kafka, Flume.
Deployment: Databricks (cloud-managed Spark), EMR, or self-hosted clusters.
The ecosystem evolves rapidly - recent additions include better Kubernetes support and Delta Lake for reliable data lakes.
Why does this matter? Spark's unification simplifies data engineering pipelines: Extract, transform, analyze, and visualize - all in one tool. No more juggling Hadoop for batch, Storm for streaming, and TensorFlow for ML.
What’s Next?
Now that we have some basics covered, why not try a simple Spark code example?
Signup for Databricks Free edition to quickly get your hands dirty: Login - Databricks
Try the below PySpark example code snippet:
Alternatively, if you want to download and install Apache Spark locally visit Downloads | Apache Spark and follow the instructions.
Check our other articles on Apache Spark Architecture, RDDs, memory management, etc. for a deeper dive and subscribe for updates!