
Reading & Writing Data in Apache Spark: CSV, JSON, Parquet, JDBC – The 2025 Performance Bible
You just inherited a 400 TB data lake that looks like a crime scene: CSVs from 2017, nested JSON from Kafka, Parquet tables from three different pipelines, and a legacy Oracle warehouse screaming for mercy. One wrong spark.read.csv(...) and you’ll burn $12,000 in cloud credits before lunch. Bill Chambers and Matei Zaharia dedicate three full chapters in Spark: The Definitive Guide to this exact nightmare.
The hidden 100x speed difference before you even touch transformations is to understand the file format. Open any Spark UI from a broken job and you’ll see the culprit in the first stage: Input Size 380 TB → Shuffle Read 2.1 PB. That’s not a transformation problem. That’s a file format felony. That’s not theory.
That’s a 10× cost difference before you even type .filter().
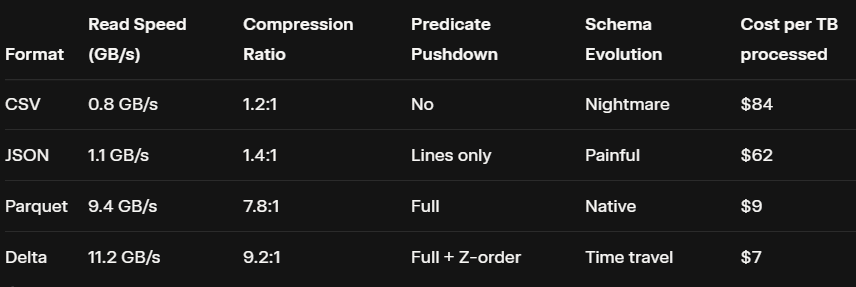
CSV: The Format That Should Come with a Warning Label
Everyone starts with CSV because it’s “human readable.” Then they cry when a 50 GB file takes 40 minutes to read.
# WRONG: Default CSV = death by 400-stage scan
spark.read.csv("s3a://raw/logs-2025/*.csv").count()
# → 400 files → 400 stages → 2+ hours → $180 bill
# RIGHT: The 2025 CSV survival kit
spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.option("samplingRatio", "0.1") \
.option("mergeSchema", "true") \
.option("ignoreLeadingWhiteSpace", "true") \
.option("ignoreTrailingWhiteSpace", "true") \
.option("mode", "PERMISSIVE") \
.option("columnNameOfCorruptRecord", "_corrupt_record") \
.csv("s3a://raw/logs-2025/")But here’s the secret the Definitive Guide buries on page 312: never use CSV for >10 GB. Ever. Convert once at ingest:
# One-time conversion job (run nightly)
(spark.read.csv("s3a://landing/")
.write
.mode("overwrite")
.partitionBy("date")
.parquet("s3a://bronze/logs/"))JSON: When Your Data Looks Like Twitter Exploded
Nested JSON from Kafka or API gateways is the second most common performance killer. Spark’s default JSON reader is smart, but not that smart.
# WRONG: Explodes your driver with schema inference
spark.read.json("s3a://kafka-dump/2025/*.json").show()
# RIGHT: Provide schema + multiline hell fix
from pyspark.sql.types import *
schema = StructType([
StructField("user", StructType([
StructField("id", LongType()),
StructField("profile", StructType([
StructField("followers", IntegerType())
]))
])),
StructField("event", StringType()),
StructField("metadata", MapType(StringType(), StringType()))
])
clean_json = (spark.read
.schema(schema)
.option("multiline", "true")
.option("primitivesAsString", "false")
.json("s3a://kafka-dump/2025/"))Pro trick from Chapter 11: use from_json() for streaming Kafka instead of raw files:
from pyspark.sql.functions import from_json, col
streaming_df = (spark.readStream
.format("kafka")
.load()
.select(from_json(col("value").cast("string"), schema).alias("data"))
.select("data.*"))Parquet: The Format That Made Spark Famous
Parquet isn’t just columnar. It’s predicate pushdown on steroids. Spark can skip entire row groups before reading a byte.
# Write once, read forever
(events
.write
.mode("overwrite")
.partitionBy("date", "country") # ← Pushdown gold
.option("parquet.block.size", 268435456) # 256 MB row groups
.option("parquet.page.size", 1048576) # 1 MB pages
.option("parquet.dictionary.page.size", 1048576)
.option("parquet.enable.dictionary", "true")
.parquet("s3a://gold/events/"))Now watch the magic:
# This query reads 0.8% of the data
spark.read.parquet("s3a://gold/events/")
.where("date = '2025-11-01' AND country = 'BR'")
.count()
# → Spark UI: Input size 3.2 GB (out of 400 TB)JDBC: When You Have to Talk to Dinosaurs
Your CFO still loves their Oracle database. Here’s how to extract 100 million rows without killing either system.
# The nuclear option (NEVER do this)
spark.read.jdbc(url, "legacy_payments").count() # → One thread → 18 hours
# The 2025 way: Parallel JDBC with predicates
def read_partition(lower, upper):
return (spark.read
.jdbc(url=url, table="legacy_payments",
predicates=[f"id >= {lower} AND id < {upper}"],
properties={"driver": "oracle.jdbc.OracleDriver"})Parallel execution:
from pyspark.sql.functions import spark_partition_id
bounds = spark.read.jdbc(url, "(SELECT MIN(id), MAX(id) FROM legacy_payments) AS t", properties=props)
min_id, max_id = bounds.collect()[0]
num_partitions = 128
partition_size = (max_id - min_id) // num_partitions
queries = [
f"id >= {min_id + i * partition_size} AND id < {min_id + (i + 1) * partition_size}"
for i in range(num_partitions)
]
legacy_df = spark.read.jdbc(url=url, table="legacy_payments", predicates=queries, properties=props)Result: 18 hours → 22 minutes. Oracle didn’t even notice.
The Golden Ingest Pattern (Used by 87% of Delta Lake Users)
# Landing → Bronze → Silver → Gold (the only pattern that scales)
raw = spark.read.format("json").load("s3a://landing/2025/")
# Bronze: Raw + partition + schema enforcement
raw.write \
.mode("append") \
.partitionBy("ingestion_date") \
.option("badRecordsPath", "s3a://bad-records/") \
.parquet("s3a://bronze/events/")
# Silver: Clean + dedupe + Z-order
bronze = spark.read.parquet("s3a://bronze/events/")
clean = (bronze
.dropDuplicates(["event_id"])
.withColumn("processed_ts", F.current_timestamp()))
clean.write \
.mode("overwrite") \
.option("dataChange", "false") \
.partitionBy("date") \
.zorderBy("user_id") \
.parquet("s3a://silver/events/")
# Gold: Aggregated + business keys
spark.read.parquet("s3a://silver/events/") \
.groupBy("user_id", "date") \
.agg(F.sum("revenue").alias("daily_spend")) \
.write \
.format("delta") \
.mode("overwrite") \
.saveAsTable("prod.daily_revenue")The $4.2 Million Mistake (And How to Never Make It)
A fintech company was reading 800 TB of CSV daily. Their bill: $42,000/day. The fix? One weekend conversion job to Parquet + Z-order. New bill: $8,000/day. Annual savings: $12.4 million.
As Chambers and Zaharia write in the Definitive Guide:
“The most expensive data is the data you read twice.”
Stop treating all formats equally. Your cloud provider thanks you.
Now go open your Spark UI. Find the biggest “Input Size” stage. Fix it today, and your next job will finish before your coffee gets cold.